We use analytics and cookies to understand site traffic. Information about your use of our site is shared with Google for that purpose.You can read our privacy policies and terms of use etc by clicking here.
Kubeflow Example
Run a Kubeflow Pipeline interacting with Seldon Deploy
Kubeflow Pipeline with Kale example using the Seldon Deploy Enterprise API
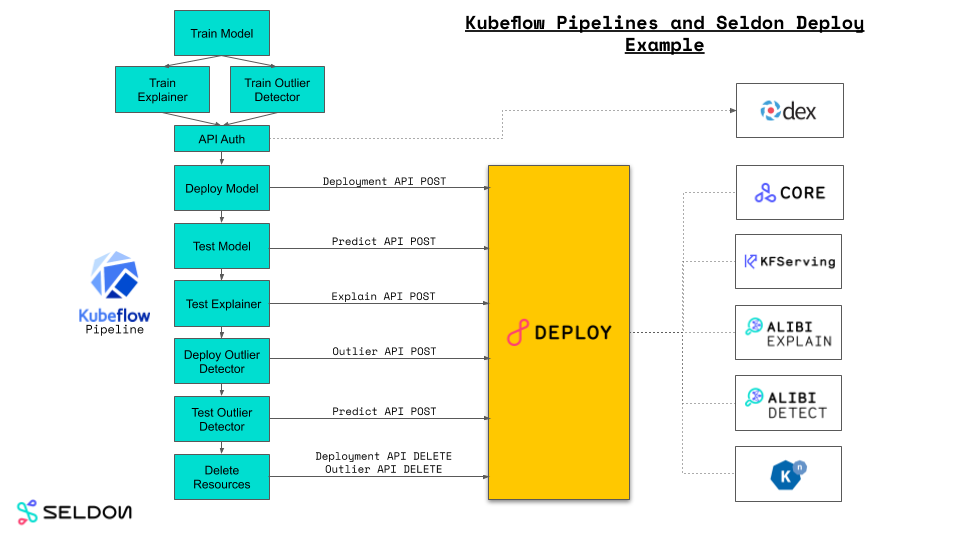
We use demographic features from the 1996 US census to build an end to end machine learning pipeline. The pipeline is also annotated so it can be run as a Kubeflow Pipeline using the Kale pipeline generator.
The notebook/pipeline stages are:
- Setup
- Imports
- pipeline-parameters
- minio client test
- Train a simple sklearn model and push to minio
- Prepare an Anchors explainer for model and push to minio
- Test Explainer
- Train an isolation forest outlier detector for model and push to minio
- Deploy a Seldon model and test using the Seldon Deploy Enterprise API
- Deploy an outlier detector with the Seldon Deploy Enterprise API
- Test the outlier detector
Prerequisites
A Seldon Deploy install, version >=1.0.0, installed with Kubeflow.
Obtain the code for this demo by running from the seldon-deploy-resources Github repository.
git clone https://github.com/SeldonIO/seldon-deploy-resources.git cd examples/seldon-core/kubeflow
GCP Setup
For a GCP cluster we need a RWX Persistent Volume for the shared data Kale needs. To set this up on GCP update and run the script create-pv.sh after setting the values for your project, Filestore name and Zone:
PROJECT=seldon-demos
FS=pipeline-data
ZONE=europe-west1-b
gcloud beta filestore instances create ${FS} --project=${PROJECT} --zone=${ZONE} --tier=STANDARD --file-share=name="volumes",capacity=1TB --network=name="default",reserved-ip-range="10.0.0.0/29"
FSADDR=$(gcloud beta filestore instances describe ${FS} --project=${PROJECT} --zone=${ZONE} --format="value(networks.ipAddresses[0])")
helm install nfs-cp stable/nfs-client-provisioner --set nfs.server=${FSADDR} --set nfs.path=/volumes --namespace=kubeflow
kubectl rollout status deploy/nfs-cp-nfs-client-provisioner -n kubeflow
The project and zone should match your GCP kubernetes cluster. FS name can be pipeline-data.
If you build the pipeline Python DSL using Kale from the notebook you will at present need to modify the created pyhton and change the Kale VolumeOp by adding a storage_class for the NFS PV, for example:
marshal_vop = dsl.VolumeOp(
name="kale-marshal-volume",
resource_name="kale-marshal-pvc",
storage_class="nfs-client",
modes=dsl.VOLUME_MODE_RWM,
size="1Gi")
RBAC Setup
The default pipeline-runner service account needs to be modified to allow creation of secrets and knative triggers.
As an admin user run:
kubectl create -f pipeline-runner-additions.yamlPipeline/Notebook Parameters
The pipeline/notebook has several core parameters that will need to be set correctly.
| Name | Default Value |
|---|---|
| DEPLOY_NAMESPACE | admin |
| DEPLOY_PASSWORD | 12341234 |
| DEPLOY_SERVER | https://x.x.x.x.x/seldon-deploy/ |
| DEPLOY_USER | admin@kubeflow.org |
| EXPLAINER_MODEL_PATH | sklearn/income/explainer |
| INCOME_MODEL_PATH | sklearn/income/model |
| MINIO_ACCESS_KEY | admin@seldon.io |
| MINIO_HOST | minio-service.kubeflow:9000 |
| MINIO_MODEL_BUCKET | seldon |
| MINIO_SECRET_KEY | 12341234 |
| OUTLIER_MODEL_PATH | sklearn/income/outlier |
If you’re not sure of your minio credentials, run kubectl get secret -n kubeflow mlpipeline-minio-artifact -o yaml and base64 decode them.
Kubeflow Notebook Server
Start a Kubeflow Notebook server with custom image seldonio/jupyter-lab-alibi-kale:0.23 (other settings default)

Test Pipeline
Assuming you have run the GCP and RBAC setup above you can launch the pipeline saved in seldon_e2e_adult_nfs.kale.py.
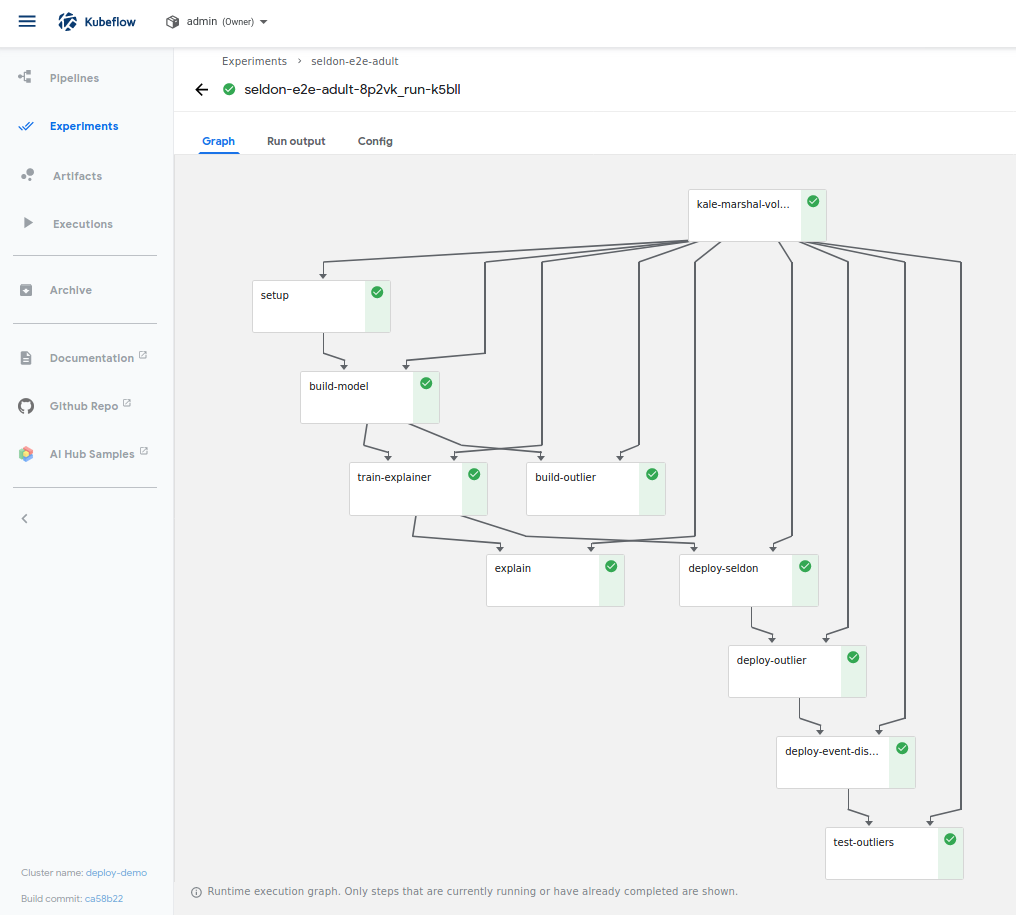
The yaml file can be uploaded to the pipelines UI and then create an experiment and a run.
Tested on
If you have tested the pipeline successfully please add a PR to extend the table below.
| K8S | Kubeflow | Knative Eventing | Seldon | KFServing | Kale | Notes |
|---|---|---|---|---|---|---|
| GKE 1.16.13 | 1.2 | 0.18 | 1.5.0 | 0.4.0 | 0.5.0 | GCP Setup above, Kale storage_class fix, RBAC update above |
| GKE 1.16.15 | 1.2 | 0.18 | 1.5.0 | 0.4.1 | 0.5.0 | RBAC update and disable istio sidecars |
Last modified December 1, 2020: kubeflow example - small tweaks (15b7c8d)