We use analytics and cookies to understand site traffic. Information about your use of our site is shared with Google for that purpose.You can read our privacy policies and terms of use etc by clicking here.
Requests to Models
Requests can be made using the user interface via different options.
Make a prediction
The prediction can be made from the UI directly by pasting or uploading content. The response is then shown on the screen.
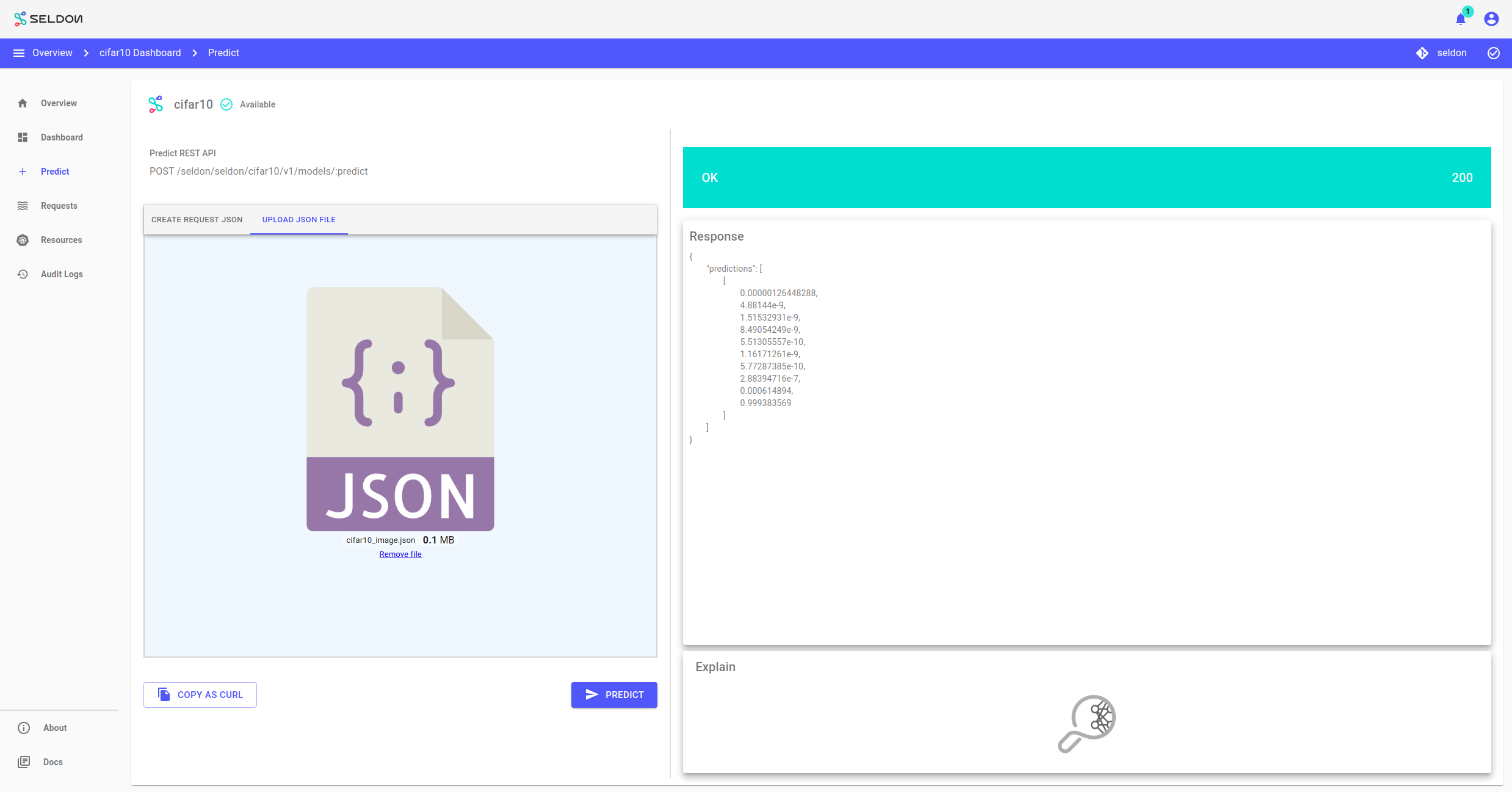
Here the path to model is displayed and an option is provided to export a curl command for manual requests.
SeldonDeployment models default to the Seldon protocol and URL form. Alternatively, the tensorflow protocol can be used and then Deploy will infer a tensorflow URL. With Seldon the model name needs to be specified as a parameter in the manifest. Content of tensorflow requests is different as explained in a seldon core notebook.
Load Test
This initiates a loadtest, which in the background is implemented using hey and exposes the same options as that tool
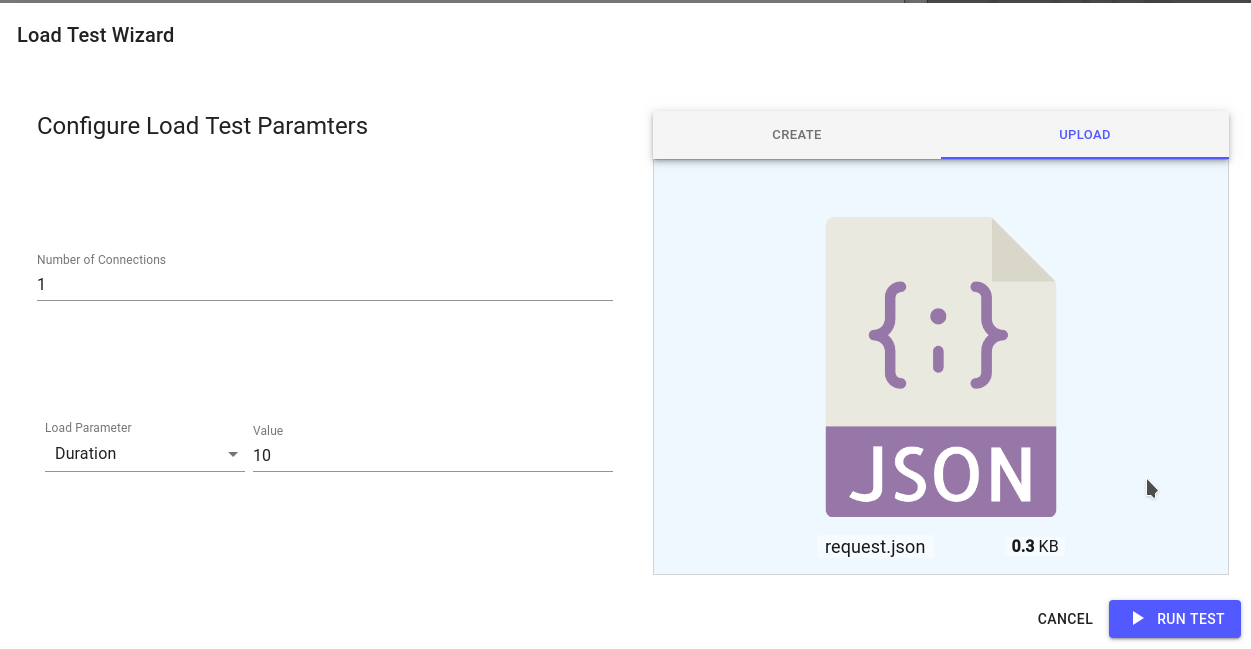
The load test runs inside the cluster so can take time to be provisioned.
Last modified August 21, 2020: Removing seldonctl usage and minor ui fixes (b8b198a)